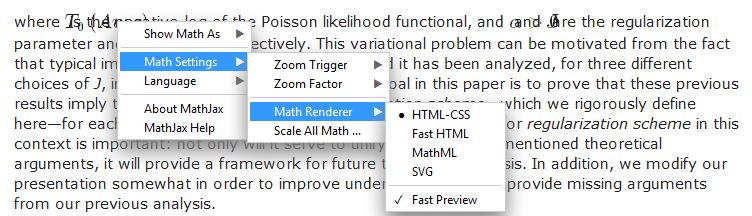
If mathematical formulas are not correctly displayed, try changing the MathJax output format.
Spring 2026
-
John Bardsley – University of Montana
Uncertainty Quantification for Inverse Problems with Poisson measurement error
Inverse problems arise when physics-based models are fit to observational data. The unknown parameters in such models are often spatially distributed and become large-scale after discretization. These parameter estimation problems are typically ill-posed, meaning that solutions are unstable with respect to errors in the data. Regularization is the standard approach to mitigate this instability.
In this talk, I will focus on inverse problems where the data follows a Poisson distribution, a common scenario in imaging applications. I will demonstrate how to implement regularization in the Poisson noise case. Then, building on the connection between inverse problems and Bayesian statistics, I will reformulate the problem within a Bayesian inference framework. This allows for uncertainty quantification through the posterior distribution. I will then present a Markov chain Monte Carlo (MCMC) method for sampling from the posterior, enabling robust parameter estimation and uncertainty analysis.
February 2, 2026 at 3:00 p.m. Math 103
-
Mark Kayll – University of Montana
Three graph families, 3 speakers, (iii) noun phrases (one talk)
Sixty years ago, Jack Edmonds published an elegant characterization of a graph \(G\)'s so-called ‘perfect matching polytope’ \({P}\) (i.e., the convex hull of the characteristic vectors of \(G\)'s perfect matchings). He described \({P}\) polyhedrally as the set of nonnegative vectors in \(\mathbb{R}^{E(G)}\) satisfying two families of constraints: ‘saturation’ and ‘blossom’. Mathematicians now call graphs for which the blossom constraints are essential Edmonds graphs and those for which the blossom constraints are implied by the others Egerváry graphs. As it turns out, the second graph class interacts nicely with more familiar ones; for example, bipartite graphs are Egerváry. This talk introduces these graph classes and shares a few results on Egerváry graphs that appeared recently in our Journal of Combinatorics article.
(Joint work with Craig Larson and Jack Edmonds)
March 2, 2026 at 3:00 p.m. Math 103
-
WiSEN research team – Jillian Cadwell, Washington State University; Makini Beck, Rochester Institute of Technology; Melinda Howard, Gonzaga University; Elizabeth Wargo, University of Idaho; Veronica Smith, Equitable Researcher & Data Justice Consultant; Ke Wu, University of Montana
Mapping Juneberries: Imagining a Future for Mentoring Graduate & Undergraduate Students in STEM Disciplines
Join us for a guided reflection activity mapping the people, experiences, and supports that shaped your path, followed by a presentation on the Juneberries mentoring model, which draws on ecological ideas of interdependence to support undergraduate and graduate students, and a practical discussion about how to start, stop, or continue specific mentoring practices to help our STEM students thrive.
March 9, 2026 at 3:00 p.m. Math 103
-
Amites Sarkar – Western Washington University
Sums, Differences and Dilates
Given a set \(A\) of integers, the sumset \(A+A\) is defined as \(A+A=\{a+b: a,b\in A\}\), and the difference set \(A-A\) is defined as \(A-A=\{a-b: a,b\in A\}\). The systematic study of sumsets was initiated in the 1960s by the Russian mathematician G A Freiman, who was motivated by several problems in number theory. Freiman proved a very influential inverse theorem for sumsets, now named after him. But he also, together with Pigarev, proved that if \(A\) is finite, then \(|A+A|^{3/4}\le|A-A|\le|A+A|^{4/3}\). This bound was later improved by Imre Ruzsa. Meanwhile, in 1967, J H Conway constructed a surprising set \(A\) of size 8 for which \(|A+A|=26>25=|A-A|\).
These results all lead to the question of bounding \(|A-A|\) in terms of \(|A|\) and \(|A+A|\). So we ask: what the are possible values \((x,y)\) such that there exists a set \(A\) with \(|A+A|=|A|^x\) and \(|A-A|=|A|^y\)? The closure of the set of such points is the feasible region \(F_{1,-1}\). Using a probabilistic technique of Ruzsa, a geometric construction of Hennecart, Robert and Yudin, methods from information theory, and the (new?) concept of the size of a fractional dilate, we prove that the point \((1.7354,2)\) is feasible (i.e., contained in \(F_{1,-1}\)). Previously, no explicit point \((c,2)\) with \(c<2\) was known to be feasible. We also present some new results about the size of the dilate set \(A+2\cdot A=\{a+2b: a,b\in A\}\), and its corresponding feasible region \(F_{1,2}\).
This is joint work with Jon Cutler and Luke Pebody.April 6, 2026 at 3:00 p.m. Math 103
-
David Ayala – Montana State University
The Tangle Hypothesis
Inspired by anyon dynamics (eg, the dynamics of electrons confined to 2 dimensional material), one can achieve a knot invariant from pure category theory. The Jones polynomial, and Alexander polynomial, are examples of such knot invariants.
In this talk, I’ll physically motivate this construction, followed by a mathematically motivated tour of the construction. Along the way, I’ll allude to the challenging aspects of the construction, and indicate the techniques used to resolve such. All the while, I'll draw pictures of knots.
April 20, 2026 at 3:00 p.m. Math 103
Available Dates for Spring 2026
April 13, 27
-
If mathematical formulas are not correctly displayed in your browser, try changing the output format of MathJax.
To do this, right-click on a formula, select "Math Settings", then "Math Renderer", and choose one of the other output formats (for example, MathML or SVG).